- Se incorporó
- 16 Noviembre 2021
- Mensajes
- 514
Nota: inconcluso
Supongo que es bien tirado de las mechas. Pero el tema plantea un ejercicio interesante y lo suficientemente complejo como para pasar el tiempo libre (tambien sirve como analgésico mental). No tiene porqué ser faisbiuk, pero me anima la idea de aprovecharme de meta
") .
.Idea
Almacenar cualquier archivo en formato de imágen dentro de fb.
En principio parecía bastante sencillo, se tomaría un archivo, convertiría su contenido a hexadecimal y de ahí de acuerdo a una tabla, se convertiría cada caracter hex del par, en un valor de 0 a 255, el que luego sería guardado secuencialmente en un canal (vector) (en escala de grises), lo que conformaría los pixeles de la imágen. Con ésto, visualmente, se vería una imagen de 1xN píxels siendo N el largo del archivo en bytes multiplicado por 2 (archivo -> hex).
Para darle formato a la imagen, mejor dicho para formar una imagen de un ancho determinado, bastaría con dividir el vector en n piezas según el ancho deseado y rellenar la pieza -1 (la del final), con un color de fondo en el extremo derecho. Finalmente todo el contenido se volcaría en un archivo PNG con compresión nivel 9.
Y fué bastante sencillo, de hecho la codificación/decodificación no es muy compleja, pero es exacta, lo que representa un problema mayúsculo, porque no es tolerante a variaciones de luminocidad, lo que a su vez se anexa a otro problema, el relleno del fondo no está lo suficientemente alejado de uno de los extremos del rango 0-255.
Para ejemplificar, usaré el siguiente texto:
What is Lorem Ipsum?
Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
Why do we use it?
It is a long established fact that a reader will be distracted by the readable content of a page when looking at its layout. The point of using Lorem Ipsum is that it has a more-or-less normal distribution of letters, as opposed to using 'Content here, content here', making it look like readable English. Many desktop publishing packages and web page editors now use Lorem Ipsum as their default model text, and a search for 'lorem ipsum' will uncover many web sites still in their infancy. Various versions have evolved over the years, sometimes by accident, sometimes on purpose (injected humour and the like).
Where does it come from?
Contrary to popular belief, Lorem Ipsum is not simply random text. It has roots in a piece of classical Latin literature from 45 BC, making it over 2000 years old. Richard McClintock, a Latin professor at Hampden-Sydney College in Virginia, looked up one of the more obscure Latin words, consectetur, from a Lorem Ipsum passage, and going through the cites of the word in classical literature, discovered the undoubtable source. Lorem Ipsum comes from sections 1.10.32 and 1.10.33 of "de Finibus Bonorum et Malorum" (The Extremes of Good and Evil) by Cicero, written in 45 BC. This book is a treatise on the theory of ethics, very popular during the Renaissance. The first line of Lorem Ipsum, "Lorem ipsum dolor sit amet..", comes from a line in section 1.10.32.
The standard chunk of Lorem Ipsum used since the 1500s is reproduced below for those interested. Sections 1.10.32 and 1.10.33 from "de Finibus Bonorum et Malorum" by Cicero are also reproduced in their exact original form, accompanied by English versions from the 1914 translation by H. Rackham.
Luego de aplicar el proceso, se tiene la siguiente imagen resultante. La que si bien puede ser descargada desde el foro y decodificada con éxito, no tiene el mismo resultado desde una plataforma que aplica una conversión de formato o un procesado de cualquier tipo a la imagen subiente (la que se está subiendo a fb).
Como se puede ver a simple vista, no hay una profundidad de color de 1 bit, ya que aun no he calado el asunto lo suficiente, lo que me llevó a los 8bits por defecto. Tambien se aprecia el background blanco de relleno abajo a la derecha de la imagen, que es méramente una forma de reconocer cuando se acaba la data y empieza la basura descartable que hace de relleno.
Profundidad de 1 bit
Pudiera ahorrarme todos los problemas leyendo valores tendientes a los extremos 0 y 255, claramente si, pero entonces tendría 2 colores posibles para encodear la data + toda la información que da soporte al formato (en éste caso PNG), lo que en términos simples volvería el archivo resultante al menos 8 veces mas pesado que el original.
Pero ésto es demostrativo, así que hay que analizarlo.
El texto del ejemplo da un total de 2316 bytes, para de una forma simple, guardar toda la data en 2 colores (blanco y negro), se tendría que almacenar la data a nivel de bits y no de bytes, danto así un total de 18528 bits, lo que daría una resolución de aprox 137x137px. Aquí aplicaría el mismo algoritmo de mas abajo, de los valores proximales pero con una distancia considerablemente mas grande, pudiéndome saltar así las conversiones de formato con diferenciales en perfiles de color, paletas y luminocidad (hasta cierto punto), pero no así reducciones/ampliaciones.
Prosiguiendo con los 8bits
Acá es donde se complica la cosa.
Como mencioné antes, con la profundidad de color tengo el rango 0-255 en una escala de grises, (donde 0 es mas oscuro y 255 mas blanco), lo que me permitió entre otras cosas, crear un alfabeto equivalente al hexadecimal. Algo como lo siguiente:
Código:
0: 0
1: 1
2: 2
3: 3
4: 4
5: 5
6: 6
7:7
8:8
9: 9
a: 10
b: 11
c: 12
d: 13
e: 14
f: 15Cuando se lee la data un archivo se obtienen datos binarios, lo que puede fácilmente ser traducido a hexadecimal. Lo pueden observar ustedes mismos con (en una terminal bash):
Bash:
xxd -p algún-archivo | tr -d '\n'
# Resultado
57686174206973204c6f72656d20497073756d3f0a4c6f72656d20497073De ahí si toman el 5 y el 7, obtendrán 57, el primer par hex, con lo que formando los siguientes pares tendrían 57 68 61 74 20... cada par es un byte (8 bits). Y si se traduce con la tabla alfabeto, caracter a caracter (sin tener en cuenta el par), se obtendría lo siguiente:
Código:
5 7 6 8 6 1 7 4 2 0 6 9 7 3 2 0 4 13 6 15 7 2 6 5 6 13 2 0 4 9 7 0 7 3 7 5 6 13 3 15 0 10 4 12 ...Lo que llevaría a una imagen totalmente negra con variaciones imperceptibles de color, efecto que para el proceso es transparente, hasta que ingresa fb a la ecuación. Y lo que en un principio a nivel de vectores de colores sería una equivalencia simple, se transforma en el problema principal. Provocando que la tabla alfabeto mute a lo siguiente:
Código:
0: 0
1: 15
2: 30
3: 45
4: 60
5: 75
6: 90
7: 105
8: 120
9: 135
a: 150
b: 165
c: 180
d: 195
e: 210
f: 225
BG FILL: 255La idea era dejar brechas entremedio, lo posiblemente grandes como para sortear la variación de la luminocidad, que no es tanta como para ser indetectable, sin caer en el por menor de la teoría profunda de JPEG y el color RGB, ni sus ecuaciones relacionadas y/o conversiones raras (aún).
Ahora sí, la siguiente conversión pretende simular la operación upload/download desde fb y la respectiva conversión para estudiar la variación en la luminocidad. PNG -> JPG -> PNG.
Código:
Original:Convertida
(Comienzo del archivo)
30:31
75:72
75:76
0:0
60:60
60:56
60:64
90:91
30:32
195:193
45:46
15:13
30:32
210:212
45:38
105:109
0:0
150:151
45:48
45:41
30:36
0:0
45:40
0:4
30:28
0:0
90:92
225:228
90:85
30:35
90:91
150:147
0:0
150:148
45:47
180:184
45:44
180:177
30:31
225:226
75:75
60:59
...
255:255
255:255
255:255
255:254
255:253
255:255
255:255
255:254
(Final del archivo)Se aprecia la variación de la luminocidad en la data, y creo que tambien ya se deja entrever la razón para seccionar en tramos la tabla alfabeto, tambien se ve al final como se aleja del valor de relleno. Para solucionar esto igual podría estirar un poco mas las secciones dependiendo de análisis futuros en relación a la distancia máxima observada con algunas muestras adicionales reales, así se podría tener un borde a cada lado del valor principal de la siguiente manera:
Código:
min en rango <----- valor ----> max en rango (contiguo ->) | min en rango <----- valor ----> max en rangoLo que se pudiera traducir en
Código:
... 187 <- 195 -> 202 | 203 <- 210 -> 217 ...Pero dado que la corrupción estaría a la vuelta de la esquina como mucho, se me vino a la mente mover dicha solución con valores mas distanciados en base al modelo HSL. Con lo que pudiera perfectamente (o no tanto) definir la tabla en el espacio RGB y de ahí convertir a HSL cada elemento, situándome en cada color distinto, partiendo su luminocidad a la mitad y situando valores intercalados con un margen desde ambos extremos.
O mas gráficamente:
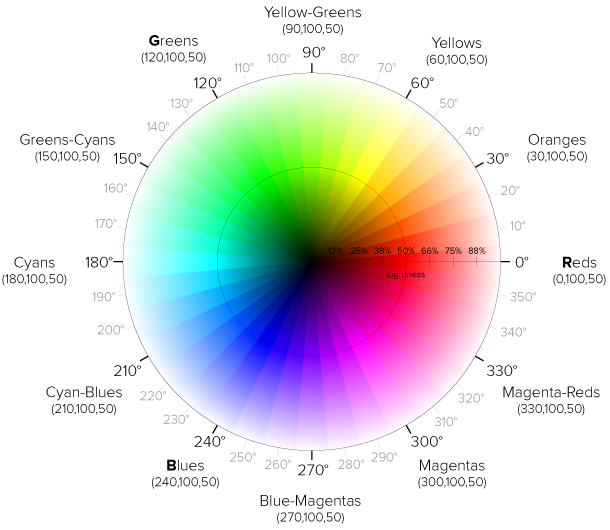
Para entender un poco mas el modelo HSL del color en el círuclo 2D. En el centro se tiene el negro y en los extremos el blanco. Si se traza una línea recta desde el centro hasta algún extremo (radio), entonces se tendrá la luminocidad, o mejor dicho, el porcentaje de luminocidad del color escogido, el que por cierto, se obtiene en base a los grados del círculo.
De ahí que y continuando con la idea anterior, pudiéndome situar al 20% de cada margen en el radio (dentro del espacio del color, justo en donde se vuelve claro y oscuro), tendría una diferenciación clara y mas de 16 puntos desde donde escoger para alimentar a la tabla alfabeto, pudiéndo situar la línea divisoria perfectamente en el 50% del radio del círculo. Pero esto supondría agrandar x3 la información contenida en el archivo PNG resultante (debido a que almacenaría 3 canales, R, G y B).
¿Por qué PNG?
Es menos complejo internamente que JPEG, e igualmente soportado por muchas plataformas, tambien tiene el canal en escala de grises que simplifica bastante las operaciones y soporta compresión, lo que transformó los 2.3kb del texto de ejemplo, en 1.5kb. Pero no necesariamente debe hacer todo el trabajo. Perfectamente se puede usar brotli en un nivel entre 3 y 5 para obtener mejores resultados, con una capa posterior de cifrado, y dejarlo en un álbum privado en fb.
Tambien existen otros formatos interesantes que se pueden usar para subir imágenes a fb, como GIF, lo que cae en la categoría de vídeos dentro de fb, situando el límite de subida en 10GB
, permitiendo así guardar una que otra imagen ISO.Lo importante acá es sobrevivir a la conversión de formato, que bien podría ahorrármela sacando directamente de la estufa un archivo JPEG en pocas líneas (pero sería aburrido). Y otra ventaja, es que el archivo resultante en PNG es mas liviano, con lo que una vez tuviera la biblioteca armada, solo entraría a descargar en formato puntual.
A ver si cuando tenga mas tiempo, me animo a terminar ésto.
pd: en mi foto de perfil está el programa en una versión anterior, para quien se anime a decodificarlo

Última modificación:

 .
.